原文:Garbage Collection In Go : Part III - GC Pacing (opens new window)
# 序言
这是讲解 Go 的垃圾回收背后的机制和语义的三部曲的第三部。本篇博文聚焦于 GC 是如何调整节奏的。
三部曲的索引如下:
- Go 的垃圾回收:第一节--语义
- Go 的垃圾回收:第二节 -- GC 追溯
- Go 的垃圾回收:第三节 -- GC 的节奏控制
# 简介
第二篇博文 展示了垃圾回收器的行为方式以及如何使用工具来查看回收器给运行的应用带来的延时。我讲解了一个真实的网页应用程序,演示生成 GC 轨迹和程序概要的方式,还说明了如何解读这些工具的输出来帮助你找到提高程序性能的途径。
那篇博文得出了和 第一篇 的一样结论:我们如果能够减轻施加给堆空间的压力,就能降低延时成本,从而提高程序性能。支持垃圾回收器的最佳策略是减少每份任务请求的内存分配次数和大小。我将会在本篇博文展示步奏随着时间的变化,控制算法是如何能够辨别出处理给定任务的最优步奏的。
# 并发的示例代码
我将会采用下面链接指向的代码
https://github.com/ardanlabs/gotraining/tree/master/topics/go/profiling/trace
这个程序计算特定话题在一堆 RSS 新闻概要文档里面的频率。这个追踪程序包含不同版本的查找算法来演示不同的并发模式。本文主要聚焦在freq、freqConcurrent和freqNumCPU这3个算法。
注意了:后续演示基于具有 12 个硬件线程 Intel i9 处理器的 Macbook Pro 配置,go 版本为 1.12.7。不同架构、操作系统和 Go 版本下看到的结果会有所不同。但所得核心结果应该保持一致。
先从 freq 版本上手。这个版本代表着非并发的、串行版本的程序,为后续并发版本提供一个比较基准。
func freq(topic string, docs []string) int {
var found int
for _, doc := range docs {
file := fmt.Sprintf("%s.xml", doc[:8])
f, err := os.OpenFile(file, os.O_RDONLY, 0)
if err != nil {
log.Printf("Opening Document [%s] : ERROR : %v", doc, err)
return 0
}
defer f.Close()
data, err := ioutil.ReadAll(f)
if err != nil {
log.Printf("Reading Document [%s] : ERROR : %v", doc, err)
return 0
}
var d document
if err := xml.Unmarshal(data, &d); err != nil {
log.Printf("Decoding Document [%s] : ERROR : %v", doc, err)
return 0
}
for _, item := range d.Channel.Items {
if strings.Contains(item.Title, topic) {
found++
continue
}
if strings.Contains(item.Description, topic) {
found++
}
}
}
return found
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
代码片段 1 展示了 freq 函数。这个串行版本的算法遍历给定文件名集合,对它们依次执行 4 项操作:打开、读取、解码和查找。它逐个对文件执行这些操作。
在本人电脑上执行这个版本的 freq 所得结果如下
代码片段 2
$ time ./trace
2019/07/02 13:40:49 Searching 4000 files, found president 28000 times.
./trace 2.54s user 0.12s system 105% cpu 2.512 total
2
3
由输出的时间可知,程序处理 4000 份文件共耗费约 2.5 秒。找到其中垃圾回收所占的时间比例是非常有用的。我们可以通过查看程序运行的追踪记录实现这个目标。由于程序启动后一直执行到退出,我们可以采用 trace 包来生成一份追踪记录。
代码片段 3
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
2
3
4
5
6
7
8
代码片段 3 展示为程序生成追踪记录所需的代码。从标准库的 runtime 文件夹导入 trace 包后,调用trace.Start 和trace.Stop()。将追踪记录定向到os.Stdout只是为了简化代码。
加上这段代码后,现在从重新编译和运行程序。别忘了把stdout 重定向到文件。
代码片段 4
$ go build
$ time ./trace > t.out
Searching 4000 files, found president 28000 times.
./trace > t.out 2.67s user 0.13s system 106% cpu 2.626 total
2
3
4
运行时间增加了 100 毫秒多一点,基本符合预期。trace捕捉了函数的每个开始调用和结束调用,精细到微妙级。关键是现在生成的 t.out 文件包含着追踪数据。
要查看追踪记录的话,这些追踪数据需要传给追踪工具。
代码片段 5
$ go tool trace t.out
执行上述命令会启动 Chrome 浏览器,初始界面如下
温馨提示:追踪工具依赖 Chrome 浏览器的内置工具,所以这个工具只能在 Chrome 里面用。
图 1
图 1 显示追踪工具启动后呈现的 9 条链接。当前重要的是第一条成为 View trace的链接。一旦选择这条链接后,我们可以到类似如下的输出
图 2
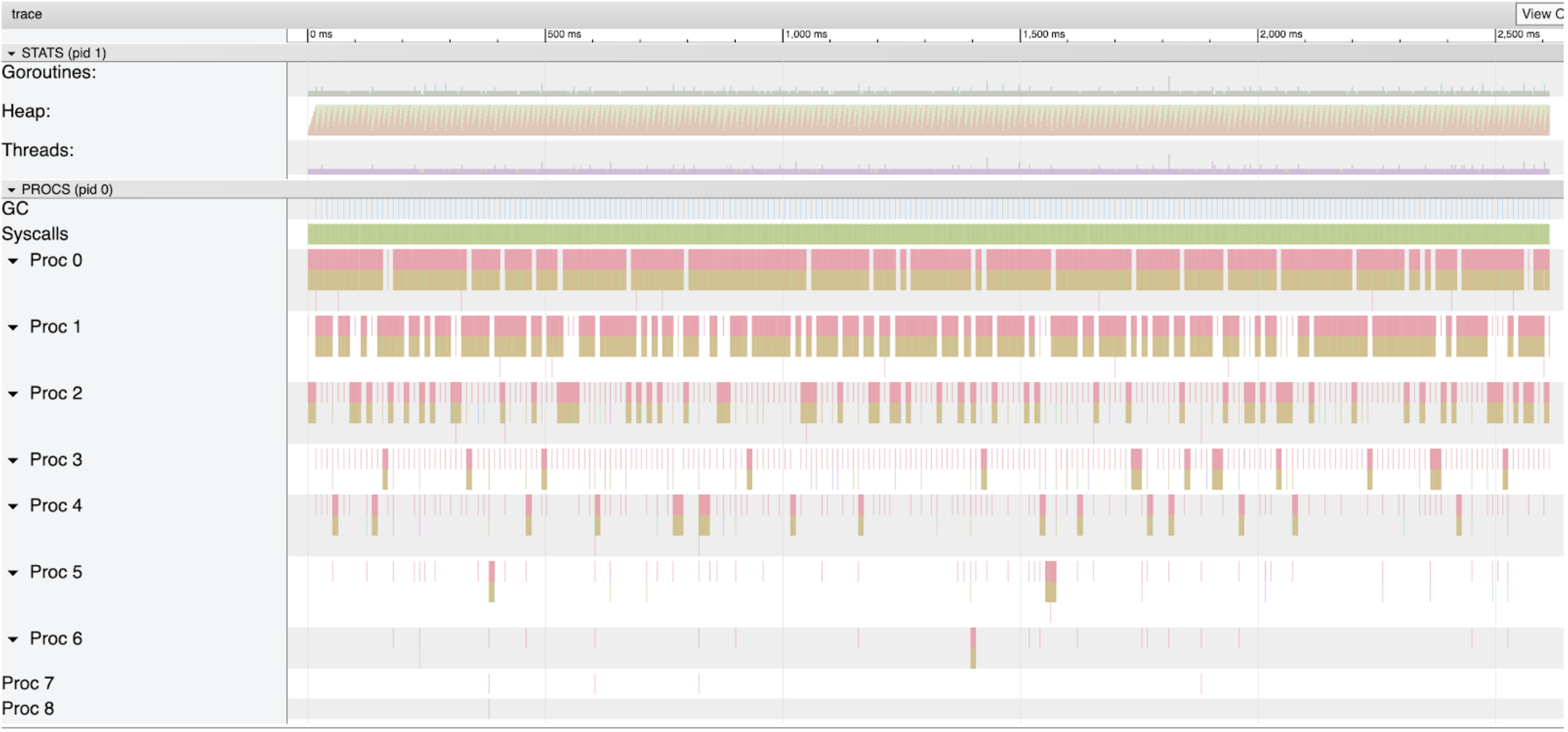
图 2 展示了程序在本人电脑运行后所得完整的追踪快照。我们在本篇博文主要着眼于和垃圾回收器相关的部分,即标为Heap的第 2 部分和GC的第 4 部分。
图 3
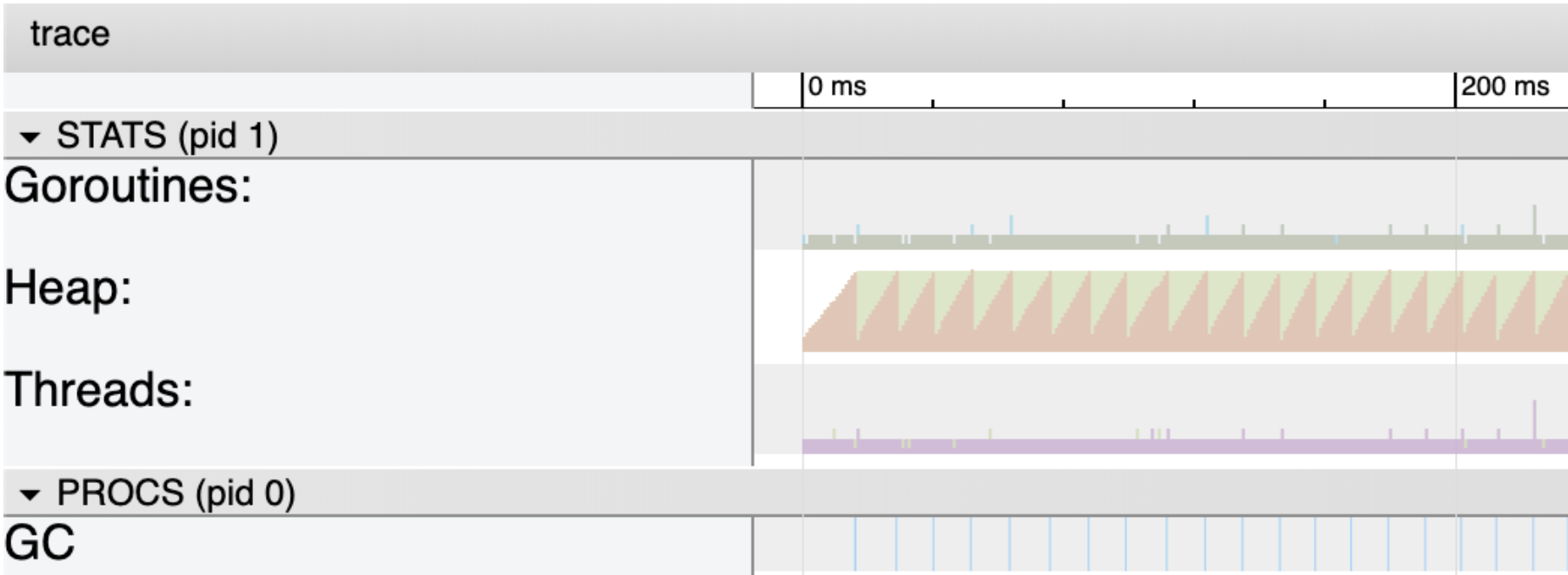
图 3 以近视角显示前 200 毫秒的追踪记录。把注意力都放在Heap(绿色和橙色的区域)和GC(底部蓝色线)。Heap部分向我们显示了两点:程序区域是不同毫秒时堆被占用的空间,绿色则表示触发下次垃圾回收所需的堆上内存。这也就是为什么每次橙色区域达到绿色区域的顶部时垃圾回收就会发生。蓝色线表示一次垃圾回收。
这个版本的程序运行期间,堆上被占用的内存大小保持在 4 MB 左右。为了查看总共发生的垃圾回收次数,用选择工具画个框圈住所有蓝色线。
图 4

图 4 演示如何用箭头工具画个蓝色框包住所有蓝色线。我们要圈住所有蓝色线。框中显示的数字表示图中被所选目标共耗费的时间。这里图中选择的区域对应着约 316 毫秒。所有蓝线选中后, 可得以下统计数据
图 5

图 5 显示图中所有蓝线覆盖的范围是从第 15.911 毫秒起的 2.596 秒。期间共发生了 232 次垃圾回收,耗费时间 64.524 毫秒,每次回收平均用时 287.121 微妙。整个程序运行共花费 2.626 秒,这也就意味着垃圾回收仅占用总运行时间约 2% 的时间。垃圾回收事实上不是运行这个程序的关键成本。
基于这个准线,一个并发算法可以用来处理同样的工作以期待能够加快程序的运行。
代码片段 6
func freqConcurrent(topic string, docs []string) int {
var found int32
g := len(docs)
var wg sync.WaitGroup
wg.Add(g)
for _, doc := range docs {
go func(doc string) {
var lFound int32
defer func() {
atomic.AddInt32(&found, lFound)
wg.Done()
}()
file := fmt.Sprintf("%s.xml", doc[:8])
f, err := os.OpenFile(file, os.O_RDONLY, 0)
if err != nil {
log.Printf("Opening Document [%s] : ERROR : %v", doc, err)
return
}
defer f.Close()
data, err := ioutil.ReadAll(f)
if err != nil {
log.Printf("Reading Document [%s] : ERROR : %v", doc, err)
return
}
var d document
if err := xml.Unmarshal(data, &d); err != nil {
log.Printf("Decoding Document [%s] : ERROR : %v", doc, err)
return
}
for _, item := range d.Channel.Items {
if strings.Contains(item.Title, topic) {
lFound++
continue
}
if strings.Contains(item.Description, topic) {
lFound++
}
}
}(doc)
}
wg.Wait()
return int(found)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
代码片段 6 实现了一种可能的并发形式的freq。这个版本的核心设计模式是 fan out 模式。对于每个docs集合列举的文件,我们会创建一个 go 协程来处理这个文件。对于 4000 个要处理的文档,就会用到 4000 个协程。这个算法的优点是能够以最简单的方式利用并发。每个协程都只需处理一个文件。协调等到每个文件处理完毕可利用WaitGroup来实现,一个原子指令会保持计数器同步。
这种算法不好的地方是无法随文档或内核数目而伸展。所有协程都会在程序刚启动时得到运行时间,这也就意味着大量内存会被迅速消耗。第 12 行的 found 变量的添加也会引入内存一致性问题。由于每个核都共享这个变量的同一条缓存线,这也会导致内存抖动。随着文件或内核数据的增加,效应更加明显。
代码在手,我们现在又可以重新编译然后运行程序了。
代码片段 7
$ go build
$ time ./trace > t.out
Searching 4000 files, found president 28000 times.
./trace > t.out 6.49s user 2.46s system 941% cpu 0.951 total
2
3
4
由代码片段 7 可知,程序现在处理同样的 4000 个文件需要 951 毫秒,实现了大约 64% 的性能提升。让我们再看看追踪记录。
图 6
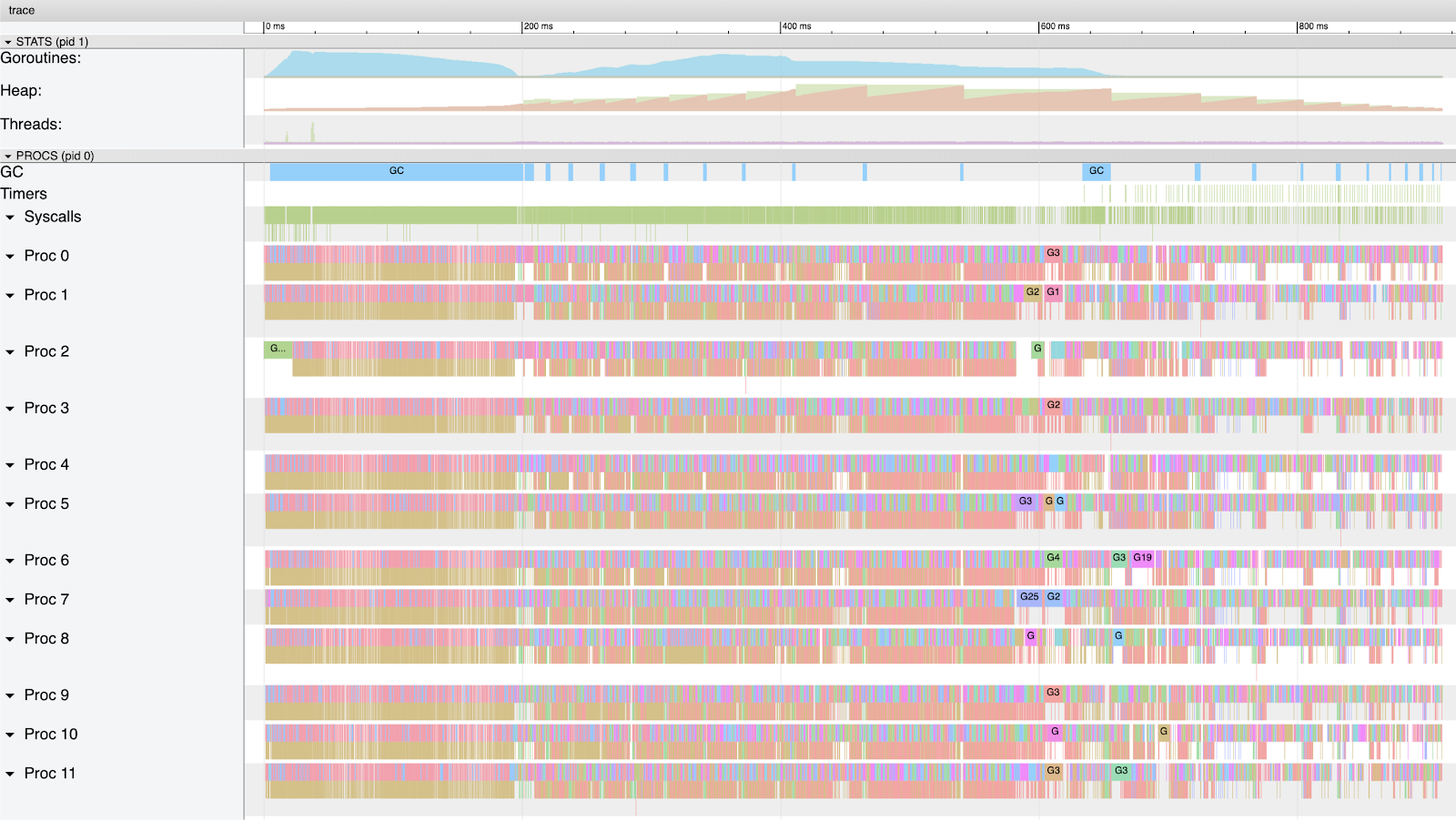
图 6 显示这个版本的程序消耗了机器更多的 CPU 容量。图像开始的密度很大。这是因为所有协程都创建出来了,它们跑起来后开始尝试向堆申请内存。第一份 4 MB 内存很快就被分配出来,GC就开始了。这个 GC 期间,每个协程都得到了运行时间,大部分在申请堆上内存时被置为等待状态。至少有 9 个协程得以继续运行,使得堆的大小在这次 GC 完成时增加到约 26 MB。
图 7

图 7 显示了第一次 GC 的大部分时间里大量协程都处于可运行和运行中状态且启动起来非常迅速的情形。可以注意到堆概览看起来是不同寻常且回收不像以往那般有节奏了。仔细一点看的话,第二次 GC 几乎立即在第一次之后就开始了。
选择这张图的所有回收的话,我们可以看到以下结果
图 8

图 8 显示所有蓝线都在从 4.828 毫秒起的 906.939 毫秒的区间内。期间共有 23 次垃圾回收,耗时 284.447 毫秒,平均回收时间为 12.367 毫秒/次。鉴于整个程序运行耗时 951 毫秒,这意味着垃圾回收占用了总运行时间约 34%。
和串行版本相比,性能和 GC 时间都有明显不同。但是,它通过运行并发地运行更多协程的方式,使得任务的完成速度加快了约 64%。代价是需要消耗机器的更多资源。不好的是最高峰时,约 200 MB 的堆内存被一度占用。
基于这个并发版本作为基准,以下并发算法试图在资源使用方面更加高效。
代码片段 8
func freqNumCPU(topic string, docs []string) int {
var found int32
g := runtime.NumCPU()
var wg sync.WaitGroup
wg.Add(g)
ch := make(chan string, g)
for i := 0; i < g; i++ {
go func() {
var lFound int32
defer func() {
atomic.AddInt32(&found, lFound)
wg.Done()
}()
for doc := range ch {
file := fmt.Sprintf("%s.xml", doc[:8])
f, err := os.OpenFile(file, os.O_RDONLY, 0)
if err != nil {
log.Printf("Opening Document [%s] : ERROR : %v", doc, err)
return
}
data, err := ioutil.ReadAll(f)
if err != nil {
f.Close()
log.Printf("Reading Document [%s] : ERROR : %v", doc, err)
return
}
f.Close()
var d document
if err := xml.Unmarshal(data, &d); err != nil {
log.Printf("Decoding Document [%s] : ERROR : %v", doc, err)
return
}
for _, item := range d.Channel.Items {
if strings.Contains(item.Title, topic) {
lFound++
continue
}
if strings.Contains(item.Description, topic) {
lFound++
}
}
}
}()
}
for _, doc := range docs {
ch <- doc
}
close(ch)
wg.Wait()
return int(found)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
代码片段 8 展示了 freqNumCPU 版本的程序。这个版本的核心涉及模式是缓存池模式。一个大小基于逻辑处理数目的协程池用于处理所有文件。如果有 12 个可用的逻辑处理器,则有 12 个协程在线。这个算法的有点是在程序保持从开始运行到结束期间的资源使用率一致。由于使用的协程数目固定,任何时候只需这 12 个协程所占内存大小即可。这也解决了由于内存抖动带来的缓存一致性问题。这是因为第 14 行的原子指令调用只会在发生少数且固定次。
算法不好的地方是更加复杂了。它引入一个通道为协程池提供所有任务。任何采用缓存池的场景,为池子确定“正确”数目的协程都是非常复杂的。基于通常情况,这里开始时为池子的每个协程分配一个逻辑处理器。然后进行负载测试或使用生产级衡量指标,池子的最后性能参数即可算出。
这个版本的代码在手,我们又可以重新构建并运行程序了。
代码片段 9
$ go build
$ time ./trace > t.out
Searching 4000 files, found president 28000 times.
./trace > t.out 6.22s user 0.64s system 909% cpu 0.754 total
2
3
4
由代码片段 9 的输出可知,现在的程序处理同样的 4000 个文件耗时 754 毫秒。程序比上一个版本快了约 200 毫秒,对这个小任务来说是非常可观的。再看看追踪记录。
图 9

图 9 显示了这个版本的程序是如何占用机器的所有 CPU 容量的。凑近一点看的话,还可以发现程序的 GC 步奏又比较整齐了,和串行版本非常类似。
图 10
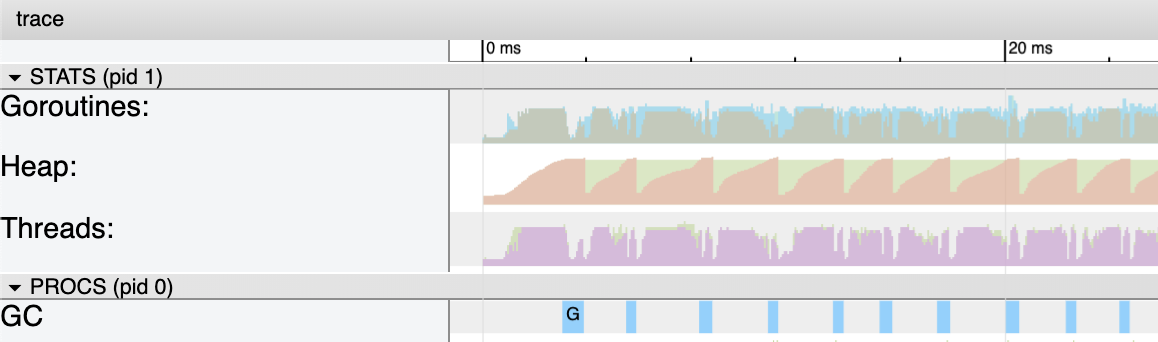
图 10 展示了更近距离视角的程序前 20 毫秒的核心衡量指标。回收时间肯定比串行版本要长,但是运行的协程有 12 个。占用的内存在整个程序运行期间一直保持在约 4 MB 的水平。再次和串行版本的程序保持一致。
选择图中所有回收可得以下结果
图 11

图 11 显示图中所有蓝线都在从 3.055 毫秒开始的 719.928 毫秒的区间内。期间共有 467 次垃圾回收,耗时 177.709 毫秒,平均回收时间为 380.535 微秒/次。基于程序运行总共耗时 754 毫秒,这意味着垃圾回收占用了总运行时间的约 25%。性能比另一并发版本提升了 9%。
这个版本的并发算法看起来随文件和处理器核数变换的伸展性要更好。带来的复杂成本在我看来是值得的。通道可以用桶代替,每个桶为每个协程存放任务。尽管可以减少通道带来的延时代价,这无疑增大了复杂度。处理更多文件或核数时,这可能会非常重要,但是需要评估复杂度带来的成本。这个就留给你自己试吧。
# 结论
对于三个版本的算法,我喜欢比较它们各自场景下 GC 的处理方式。处理所有文件所需总内存并没有随版本有所变化。变的是程序内存分配的方式。
仅有一个协程时,基本 4MB 就足够了。程序一下子把所有任务都扔给运行时的情况下,GC 任由堆内存增长,减少了回收次数但是拉长了回收时间。程序控制任何时间能够处理的任务数目时,GC 能够再次保持堆小规模,增加回收次数而执行短回收。GC 采用的每种方式本质上都是使得程序运行收到 GC 的影响最小化。
| Algorithm | Program | GC Time | % Of GC | # of GC’s | Avg GC | Max Heap |
|---|---|---|---|---|---|---|
| freq | 2626 ms | 64.5 ms | ~2% | 232 | 278 μs | 4 meg |
| concurrent | 951 ms | 284.4 ms | ~34% | 23 | 12.3 ms | 200 meg |
| numCPU | 754 ms | 177.7 ms | ~25% | 467 | 380.5 μs | 4 meg |
freqNumCPU版本还有其他附带效果,例如能够更好地处理缓存一致性,对程序是有用的。但是,程序的 GC 总时间的差值是非常相近的,约 284.4 ms 对 177.7 毫秒。某些时候,本人机器上面运行这些程序所得数字甚至更加接近。基于 Go 1.13.beta.1 版本进行实验时,我发现两个算法耗时相等。这可能意味着后续会有一些优化使得 GC 能够更好地预测自己的运行方式。
以上所有都给了我把大量工作扔给运行时的信心。例如一个网络服务使用 50k 个协程,实际上是和第一个并发版本相似的 fan out 模式。GC 会分析任务量并找出提供服务的最优节奏。至少对我来说,接受它们来换取不用考虑任何这些东西的代价是值得的。